Sharp-P
In computational complexity theory, the complexity class #P (pronounced "number P" or, sometimes "sharp P" or "hash P") is the set of the counting problems associated with the decision problems in the set NP. More formally, #P is the class of function problems of the form "compute ƒ(x)," where ƒ is the number of accepting paths of a nondeterministic Turing machine running in polynomial time. Unlike most well-known complexity classes, it is not a class of decision problems but a class of function problems.
An NP problem is often of the form, "Are there any solutions that satisfy certain constraints?" For example:
- Are there any subsets of a list of integers that add up to zero? (subset sum problem)
- Are there any Hamiltonian cycles in a given graph with cost less than 100? (traveling salesman problem)
- Are there any variable assignments that satisfy a given CNF formula? (Boolean satisfiability problem)
The corresponding #P problems ask "how many" rather than "are there any". For example:
- How many subsets of a list of integers add up to zero?
- How many Hamiltonian cycles in a given graph have cost less than 100?
- How many variable assignments satisfy a given CNF formula?
Clearly, a #P problem must be at least as hard as the corresponding NP problem. If it's easy to count answers, then it must be easy to tell whether there are any answers. Just count them, and see if the count is greater than zero.
One consequence of Toda's theorem is that a polynomial-time machine with a #P oracle (P#P) can solve all problems in PH, the entire polynomial hierarchy. In fact, the polynomial-time machine only needs to make one #P query to solve any problem in PH. This is an indication of the extreme difficulty of solving #P-complete problems exactly.
Surprisingly, some #P problems that are believed to be difficult correspond to easy P problems. For more information on this, see #P-complete.
The closest decision problem class to #P is PP, which asks if a majority (more than half) of the computation paths accept. This finds the most significant bit in the #P problem answer. The decision problem class ⊕P instead asks for the least significant bit of the #P answer.
The complexity class #P was first defined by Leslie Valiant in a 1979 paper on the computation of the permanent, in which he proved that permanent is #P-complete.[1]
Larry Stockmeyer has proved that for every #P problem P there exists a randomized algorithm using oracle for SAT, which given an instance a of P and ε>0 returns with high probability a number x such that 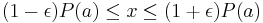 . The runtime of the algorithm is polynomial in a and 1/ε. The algorithm is based on leftover hash lemma.
. The runtime of the algorithm is polynomial in a and 1/ε. The algorithm is based on leftover hash lemma.
References
- ^ Leslie G. Valiant (1979). "The Complexity of Computing the Permanent". Theoretical Computer Science (Elsevier) 8 (2): 189–201. doi:10.1016/0304-3975(79)90044-6.
External links
|
|||||||||||||||||